
In this post we’ll walk through an issue I faced during one of the projects where source data (MySQL DB in our case) was so huge that ODI was not able to handle & was giving GC Overhead limit exception.
We took out the source query & filtered the data according to a specific year and ran again. This time since the source query was substantiated to a limit was giving out the appropriate results.
This gave us the idea to develop some kind of loop in ODI that will recursively run the interface/mapping iterating through the years present in source.
This article mainly focuses on developing this loop by using variables in ODI that will refresh and run our interface/mapping iteratively.
First of all, lets focus on different type of variables offered by ODI and how we can leverage them for our development.
Set Variable: A Set Variable step of type Assign sets the current value of a variable. We will use this to initialize our counter variable.
Refreshing Variable: We will extensively use this kind of variable.A Refresh Variable step allows you to re-execute the command or query that computes the variable value. We will create counter using this type of variable which will increment itself every time this variable is referenced.
There are other variables offered as well such as evaluate, declare & increment variable but we are not going to discuss them here as they will not be required in our case. You can always google them though.
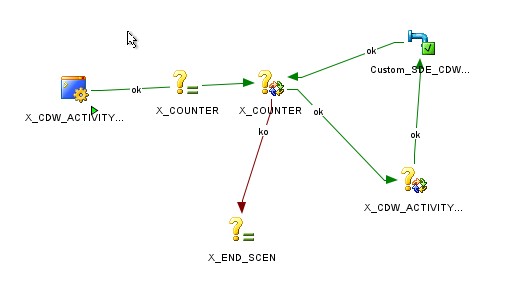
Now, we’ll go through the above diagram in sequential order explaining each of the step in detail.
- (Requirement) Each time the mapping runs, it should truncate the existing data first.
- I have created procedure having truncate statement & tied that as the first execution step. Guys please note that there are multiple ways you can handle this but I found this approach a bit easy & quick.
- X_COUNTER: The 2nd & 3rd object in our diagram is referencing the same variable but is performing different operation in both cases.
- X_COUNTER when referenced as a set variable in 2nd step is used to initialize the counter to a value of -1
- Now, in the 3rd step same variable is used as a refresh variable which will increase every time it is referenced. Let me explain the query behind this variable
- X_CDW_ACTIVITY_YEAR: This again is are refresh variable which will output the specific year based upon the x_counter value. Below is the query:
The above query will return a single year based upon our X_COUNTER value since select query will list down all the distinct years in increment order and limit will extract the specific value based on the number(e.g. if x_counter=2 then limit 2,1 will fetch the 2nd value). Also, please note that our source is MySQL and the above query may not work for other db(its just one way of getting value based upon counter, you can use other approach as well)
- Mapping: After refreshing all the variables, next step will be the main mapping, from where the final source query will generate. We have to just make sure to add the filter in our mapping for the particular column i.e.

Hope you understood the concept. Please feel free to comment for any doubts or suggestions. Happy coding 🙂


Hi Sri,
The best way to handle this is to create one package and add the scenarios from load plan in that using variable loops. Generate the scenario for that package and use that in load plan.
Thanks,
Parikshit Agarwal
Hi Parikshit,
You have given a valuable information but i have some sort of different requirement like i have to implement the same in load plan by using the variable.
Please let me know if you have some idea on that.
Thnaks,
Sri Nataraj